
Servizio REST per splittare documenti PDF leggendo barcode, nuovo esperimento in SAP BTP Cloud Foundry
Un altro esperimento con barcode, pdf, python e SAP BTP, continuando quando sperimentato qui e qui.
Immaginiamoci una situazione concreta: un operatore carica mediante scanner un documento (di una o più pagine) con appiccicato un barcode sulla prima pagina, e questo documento deve essere caricato in SAP e associato a un oggetto di business (una fattura, una bolla di entrata merce, un ordine, un qualcosa) precedentemente predisposto con lo stesso barcode. La situazione può essere gestita con meccanismi già disponibili in SAP: il documento entra nell'ERP, viene salvato nell'archivio documentale, viene mandato al servizio OCR che restituisce il valore letto dal barcode sulla prima pagina, e viene effettuata l'associazione interna.
Adesso immaginiamo una simpatica variante: il cliente appiccica il barcode sulla prima pagina di ciascun documento, ma decide di piazzare il plico di fogli tutti assieme nella multifunzione che quindi produce un grosso pdf con tutti i documenti. A questo punto è un problema, perchè nel meccanismo che abbiamo implementato prima in SAP i documenti entrano uno alla volta. La cosa più sana che potremmo fare in questo momento è usare un qualcosa che divide il plico in N documenti, analizzando i barcode (dove c'è il barcode è la prima pagina di un documento), e poi mandi ciascun documento individualmente a SAP.
Supponendo di avere un middleware in grado di fare da tramite (fare la richiesta, ricevere i file individuali e mandarli a SAP), proviamo a vedere come potremmo mettere a disposizione di questo middleware un servizio in grado di splittare il documento, da installare nella SAP BTP.
Supponiamo di volerlo fare in Python. Tutto il codice mostrato in questo esempio è disponibile su questo repo GitHub.
La prima cosa che dobbiamo fare è impostare un servizio REST (che chiameremo fantasiosamente barcodesplit) di tipo POST che riceverà in ingresso un PDF (nel payload della richiesta) e restituirà un body multipart contenente i singoli file. Possiamo predisporre il servizio con la libreria Flask.
app = Flask(__name__)
@app.route('/barcodesplit', methods=['POST'])
def barcodesplit():
...A questo punto il metodo request.getdata() di Flask ci restituisce il contenuto dell'oggetto passato. Lo diamo in pasto a pdf2image, che lo converte in una serie di immagini (che potremo poi passare al detector di barcode). Impostiamo una risoluzione di 400dpi (che abbiamo verificato essere sufficiente a interpretare i barcode che usiamo) e una conversione in bianco e nero, che è più veloce.
pages = pdf2image.convert_from_bytes(
request.get_data(),
dpi=400,
grayscale=True
)Il passo successivo è analizzare le pagine una a una, alla ricerca dei barcode, e segnarci il numero delle pagine in cui effettuare lo split del documento di partenza. Restituiamo una lista di tuple, ciascuna delle quali contiene un numero di pagina (l'inizio del sottodocumento) e il valore del barcode.
Come bonus facciamo la verifica del tipo barcode e il match con una regexp. Il motivo della verifica è che nei documenti potrebbero esserci altri barcode oltre a quelli che andiamo ad appiccicare, e quindi è fondamentale ignorarli riconoscendo la struttura dei nostri (in questo esempio, prendiamo solo barcode CODE128 con valore numerico preceduto da prefisso "DOC").

barcode_pattern = '^DOC[0-9]+$'
barcode_compiled_pattern = re.compile(barcode_pattern)
barcode_type = 'CODE128'
split_positions = []
for index, page in enumerate(pages):
found_barcodes = pyzbar.decode(page)
for obj in found_barcodes:
print(f"Barcode {obj.data.decode('utf-8')} (type {obj.type}) found on page {index}")
if (obj.type != barcode_type): continue
if (not barcode_compiled_pattern.match(obj.data.decode('utf-8'))): continue
split_positions.append((index, obj.data.decode('utf-8')))Mi sono creato un documento di esempio con un pò di barcode (validi e non). Il risultato della procedura di cui sopra assomiglia a questo: una lista di tuple con pagina iniziale e barcode per ciascun sottodocumento.
[(0, 'DOC001'), (3, 'DOC002'), (5, 'DOC003'), (6, 'DOC004'), (8, 'DOC005')]Ora possiamo effettuare lo split vero e proprio. Iniziamo inserendo il request.get_data() in uno stream binario, e lo diamo in pasto a PdfFileReader.
Per ciascuna delle posizioni in cui dobbiamo splittare il documento, identifichiamo anche l'ultima pagina (che corrisponde alla prima pagina dello split successivo, a meno che non siamo all'ultimo split e in tal caso corrisponderà all'ultima pagina del documento di partenza).
A questo punto, per ciascuno split creiamo un PdfFileWriter e ci scriviamo dentro una a una le pagine necessarie (addPage()), e per finire andiamo a scrivere il risultato in uno stream binario. Man mano che raccogliamo questi documenti li andiamo a inserire in un dizionario di tuple che rappresenteranno le parti del nostro http multipart di risposta, corredati di nome della parte, nome del file di output e tipo (application/pdf). In questo esempio, impostiamo il nome del file come contatore-barcode.pdf (esempio: 001-DOC123456.pdf).
with io.BytesIO(request.get_data()) as data:
inputpdf = PdfFileReader(data)
response_data = {}
for i, element in enumerate(split_positions):
(first_page, barcode) = element
if i < len(split_positions)-1:
last_page = split_positions[i+1][0]
else:
# For the last split position, the last page
# is the last page of the document.
last_page = inputpdf.numPages
output = PdfFileWriter()
for page in range(first_page, last_page):
output.addPage(inputpdf.getPage(page))
with io.BytesIO() as tmp:
output.write(tmp)
response_data[f"part-{i}"] = (f"{i:03}-{barcode}.pdf", tmp.getvalue(), 'application/pdf')Per concludere, possiamo costruire il nostro multipart di risposta passando il dizionario creato prima a MultipartEncoder (dalla libreria requests_toolbelt).
m = MultipartEncoder(response_data)
return Response(m.to_string(), mimetype=m.content_type) E questa è fatta, abbiamo il nostro file "barcode.py" che contiene il servizio REST.
NOTA: il programma descritto sopra e riportato nel repo è ovviamente un esempio didattico, non è ottimizzato e non ha alcuna gestione degli errori. Fatemi il piacere di non prenderlo e metterlo in produzione così com'è, e se lo fate non lamentatevi poi con me.
Docker
Il passo successivo è impacchettare il tutto in un container Docker.
Rispetto a quando descritto nel precedente post ho deciso di far servire il servizio Flask, anzichè dal suo server http predefinito (che dovrebbe essere usato solo per test), da Gunicorn, un server scritto in Python e pensato proprio per questo genere di servizi. Quindi, anzichè chiamare app.run() dentro lo script python, prepariamo un file bash che si occuperà di eseguire gunicorn e dargli in pasto il nostro servizio flask (l'oggetto "app" nel file "barcode"). Una cosa del genere:
#!/bin/sh
gunicorn --chdir /app barcode:app -w 1 --threads 1 -b 0.0.0.0:3333A questo punto ci occorre un dockerfile, ovvero un file che descrive come creare la nostra immagine docker.
- Partiamo da una immagine Python 3.10 in versione slim (quindi con meno librerie preinstallate di default e quindi dimensioni più ridotte).
- Creiamo la cartella di lavoro /app.
- Eseguiamo apt-get per aggiornare il repository e installare alcune dipendenze di sistema.
- Eseguiamo pip per installare le librerie python necessarie.
- Aggiungiamo i nostri file (barcode.py e entry_point.sh).
- Segnaliamo la necessità di esporre la porta 3333.
- Selezioniamo come entry point il nostro script bash, che sarà quindi eseguito all'avvio dell'immagine docker.
FROM python:3.10-slim
RUN mkdir -p /app
WORKDIR /app
RUN apt-get update && apt-get -y install zbar-tools poppler-utils
RUN apt-get clean
RUN pip install flask pyzbar pdf2image cfenv gunicorn PyPDF2 requests_toolbelt
ADD barcode.py entry_point.sh /app/
EXPOSE 3333
ENTRYPOINT ["./entry_point.sh"]Ora possiamo creare l'immagine. Si noti che il prefisso prima del nome dell'immagine dev'essere il nome del proprio utente su Dockerhub (altrimenti non sarà possibile caricarvi l'immagine). A meno che non vogliamo limitarci a testare in locale senza caricarlo sulla BTP, in tal caso il prefisso non è necessario.
docker build -t piccimario/barcode-split-cf:0.1 .Una volta creata l'immagine possiamo avviare una istanza locale per testare il tutto.
docker run -t -i --rm -p 3333:3333 piccimario/barcode-split-cf:0.1Possiamo testare la chiamata in locale usando per esempio Postman, e questo file. Effettuiamo una chiamata a http://localhost:3333/barcodesplit passando come body (binary) il pdf, e il risultato sarà qualcosa del genere:
Nell'immagine sopra si vede la prima parte del multipart, preceduta dal saparatore, con il pdf all'interno. Successivamente nella risposta sono presenti tutte le altre parti.
Per terminare l'istanza possiamo semplicemente premere Ctrl+C (l'opzione --rm fa sì che l'istanza terminata sia automaticamente rimossa dal sistema).
Ma che me ne faccio di questo multipart?
La risposta con i PDF in un multipart è una soluzione comoda per un sistema automatizzato, in grado di estrarre i singoli documenti per inviarli a un ERP, ma non è comodissima per effettuare test. Come faccio a provare il servizio e verificare i singoli file restituiti, visto che sono tutti mischiati in una unica risposta?
Possiamo costruirci un semplice script Python di test che, dopo aver chiamato il nostro servizio, si preoccupa di estrarre i PDF dal multipart e salvarli come singoli file su disco, per consentirci di verificarli.
Il seguente script legge il pdf da inviare (disponibile nel repo del progetto), lo invia al servizio in localhost e riceve la risposta. Divide il multipart usando MultipartDecoder (nella libreria requests_toolbelt). Fa un pò di magheggi sull'header di ciascuna parte per recuperare il nome file da scrivere e infine scrive nella cartella corrente un file per ciascuna parte, con il contenuto estratto dalla risposta.
import requests, os, re
from requests_toolbelt.multipart import decoder
# File di test da inviare
with open('./test_bc_multipli_doc.pdf', 'rb') as f:
data = f.read()
# Riceve risposta dal servizio
res = requests.post(
url='http://localhost:3333/barcodesplit',
data=data,
headers={'Content-Type': 'application/octet-stream'}
)
# Estrae multipart risposta
multipart_data = decoder.MultipartDecoder.from_response(res)
# Analizza singole parti del multipart
r = re.compile('^filename="([A-Za-z0-9-\.]+)"$')
for part in multipart_data.parts:
headers = {k.decode(): v.decode() for k,v in dict(part.headers).items()}
content_disp = [x.strip() for x in headers['Content-Disposition'].split(';')]
filename = [r.search(x).group(1) for x in content_disp if r.match(x)][0]
with open(os.path.join('./', filename), 'wb') as file:
file.write(part.content)NOTA: anche in questo caso non è prevista alcuna gestione degli errori, è solo uno script scritto in fretta&furia per fare un test. Non prendetemi come esempio.
Il risultato, usando il file di test nel repo, è questo:
E questo è il contenuto del primo file (000-DOC001.pdf):

Funziona! Si noti che sulla seconda pagina c'è un barcode NON valido (non inizia con DOC...), quindi è corretto che lì non venga effettuata la divisione.
SAP Cloud Foundry
Seguendo i passaggi descritti in un precedente post possiamo caricare l'immagine sul nostro account DockerHub, e da lì creare il servizio su un account di trial della SAP BTP Cloud Foundry.
docker push piccimario/barcode-split-cf:0.1cf logincf push barcode-split --docker-image piccimario/barcode-split-cf:0.1 --docker-username piccimario -k 512M -m 512MVerifichiamo nell'interfaccia web della BPT che il servizio esista e sia attivo:


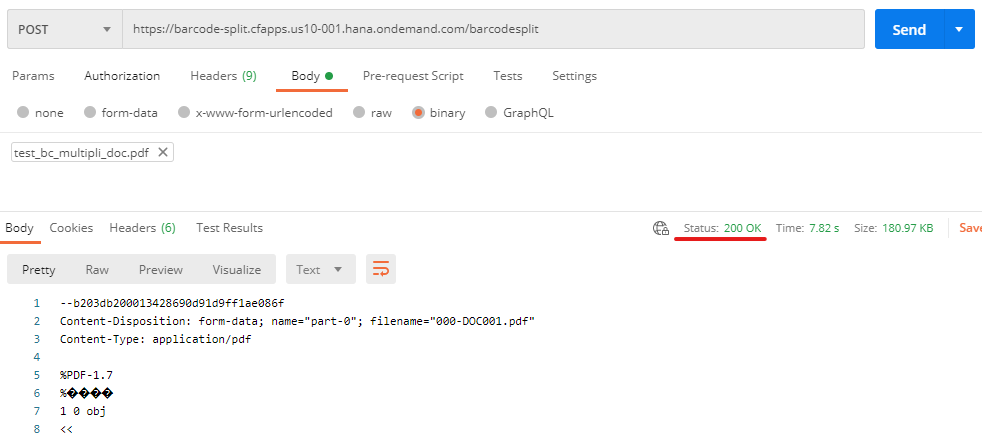
A questo punto possiamo eseguire il nostro script di test dopo averlo modificato per puntare all'endpoint "barcodesplit" del servizio esposto nella BTP, nel mio caso
https://barcode-split.cfapps.us10-001.hana.ondemand.com/barcodesplit(oppure testarlo sl volo con Postman...)
E voilà, funziona!
Alla prossima!