
Project management con Python: calcoliamo un Gantt
Oggi mi sono trovato ad affrontare un task manuale, e ho deciso di complicarmi la vita (come di consueto) inventandomi uno script Python per fare il lavoro al posto mio. E, nonostante tutto, si è rivelato un buon investimento in termini di tempo risparmiato, e mi ha anche offerto una buona idea per un post sul mio blog. Quindi direi che è stato un buon affare :-)
Il problema è il seguente. Supponiamo di avere una serie di attività da svolgere in sequenza, una dopo l'altra. Ciascuna attività "costa" un tot di giornate di lavoro. Adesso supponiamo di avere a disposizione un tot di mesi, e per ciascuno di essi un certo numero di FTE (full time equivalent), ciascuno dei quali rappresenta il lavoro svolto da un programmatore impiegato full time (quindi se ho due programmatori full time sono 2 FTE, se ho 4 programmatori impiegati sul progetto al 50% sono.. ancora 2 FTE). Dobbiamo valutare indicativamente quando ciascuna fase del progetto inizia e finisce.
Una valutazione del genere si può fare semplicemente con carta&penna (o excel, se proprio ci vogliamo male). Supponiamo per esempio di avere nel primo mese 5 programmatori full time (5 FTE), che per 20 giorni lavorativi al mese fanno 100 giornate di lavoro. Se il primo task cuba 120 giorni di lavoro, il primo mese sarà tutto occupato e il task occuperà anche le prime 20 giornate del mese successivo. Poi inizia il secondo. E così via.
Ora proviamo a farlo con Python, che è più divertente che farlo con carta&penna. Useremo un notebook Jupyter (così possiamo vedere i risultati passo passo), pandas come libreria per l'elaborazione (non strettamente necessaria, potevamo anche fare senza) e pyplot per disegnare un bel gantt alla fine.
Per prima cosa importiamo le nostre dipendenze:
import pandas as pd
import plotly.express as px
import datetime
from calendar import monthrangePrepariamo la nostra lista ordinata di task. Questo passo normalmente è il risultato finale di un'altra elaborazione, ad esempio per estrarre/sommare le stime da uno o più file excel, ma il risultato finale è questo: una lista di oggetti, ciascuno dei quali contiene la chiave "activity" con la descrizione del task e la chiave "total" con il numero di giorni necessari a completarlo.
tasks = [
{'activity': '1', 'total': 200},
{'activity': '2', 'total': 150},
{'activity': '3', 'total': 40},
{'activity': '4', 'total': 100},
{'activity': '5', 'total': 80},
{'activity': '6', 'total': 30},
{'activity': '8', 'total': 70}
]Adesso prepariamo la lista dei mesi su cui andremo a "spalmare" le giornate di lavoro. Nel nostro caso costruiremo un dataframe pandas, con alcuni valori compilati a manina e altri calcolati. In particolar modo, carichiamo a mano i mesi (si potrebbe automatizzare) e gli FTE disponibili per ciascun mese. Consideriamo un fisso di 20 giorni lavorativi al mese e un'efficienza dell' 80% e usiamo questi valori per calcolare il numero di giorni di lavoro effettivamente disponibili per ciascun mese.
months = pd.DataFrame(
list(zip(
['2023-09', '2023-10', '2023-11', '2023-12', '2024-01', '2024-02', '2024-03', '2024-04', '2024-05'],
[5, 6, 5, 6, 5, 6, 4, 7, 6]
)),
columns = ['month', 'fte']
)
months['days_month'] = 20
months['dev_efficiency'] = 0.8
months['days_avail_tot'] = months['days_month'] * months['fte'] * months['dev_efficiency']
months['days_avail'] = months['days_avail_tot']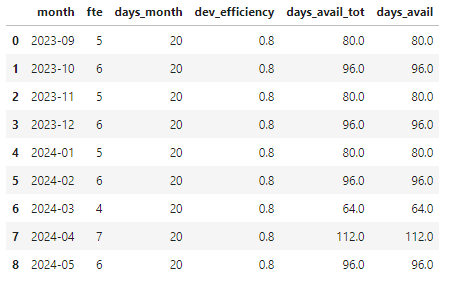
Si noti che abbiamo predisposto due colonne con i giorni disponibili: una che rimarrà così com'è, come dato informativo, e l'altra da cui andremo a scalare man mano i giorni attribuiti ai diversi task.
Prima di proseguire, predisponiamo per ciascun task una colonna vuota (ci servirà per segnare i giorni allocati per quel mese e quel task).
for task in tasks:
months[task['activity']] = 0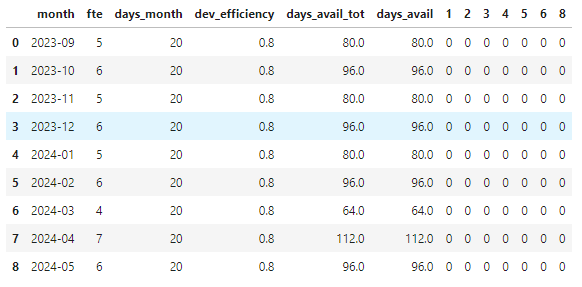
A questo punto arriva la parte divertente. Per ciascun mese, prendiamo ciascun task con giorni da allocare in sequenza, e per ciascuno cerchiamo di "consumare" la colonna "days_avail". Se finiscono i giorni disponibili vuol dire che per quel mese abbiamo finito e passiamo oltre; se invece finiscono i giorni del task passiamo a consumare il task successivo.
Siccome per qualche motivo stiamo usando un dataframe pandas, dobbiamo iterare sulle righe con iterrows(). Ad ogni iterazione facciamo una copia della riga, la modifichiamo con l'algoritmo e poi usiamo questa copia per rimpiazzare la riga originale.
Una cosa del genere:
for task in tasks:
months[task['activity']] = 0
for index, row in months.iterrows():
newrow = row.copy()
for task in tasks:
if (task['total'] != 0):
if (newrow['days_avail'] < task['total']):
newrow[task['activity']] = newrow['days_avail']
task['total'] -= newrow['days_avail']
newrow['days_avail'] = 0
else:
newrow[task['activity']] = task['total']
newrow['days_avail'] -= task['total']
task['total'] = 0
months.iloc[index] = newrow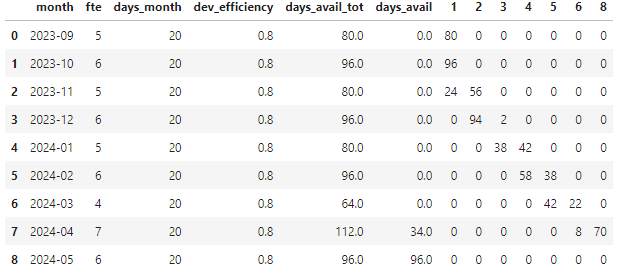
Funziona! Come si vede, il primo task occupa i primi due mesi per intero più 24 giorni nel terzo (quindi grossomodo un quarto), il secondo task 56 giorni nel terzo e quasi tutto il quarto, e così via.
Possiamo abbellire la tabella (e verificare le somme :-) ) aggiungendo manualmente una riga di totali. Con pandas posso calcolare i totali usando semplicemente il comando "sum" (numeric_only), ma questo mi calcola anche i totali sulle colonne dei giorni/mese e dell'efficienza, che non mi interessano. Fortunatamente posso grezzamente andare poi a sbiancare i totali che non voglio, così, tanto per complicarmi la vita.
months.loc['Total'] = months.sum(numeric_only=True, axis=0)
# Colonne di cui voglio mostrare il totale
columns_to_sum = []
for task in tasks:
columns_to_sum.append(task['activity'])
# Colonne da sbiancare (tutte quelle che non sono nella lista di prima)
columns_to_blank = []
for column in list(months.columns):
if column not in columns_to_sum:
columns_to_blank.append(column)
for column in columns_to_blank:
months.loc['Total', column] = ''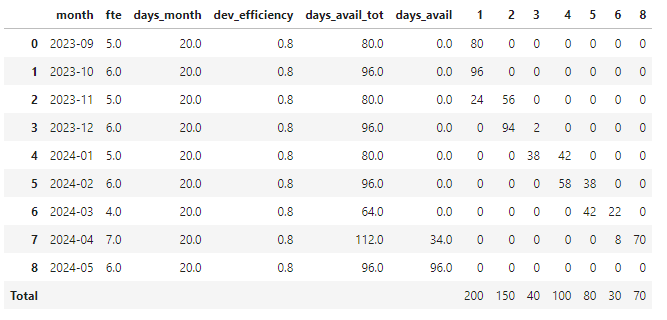
Disegnare il Gantt
A questo punto per rendere tutto più chiaro possiamo disegnare il nostro Gantt. Problema: per disegnare il grafico mi occorre stabilire delle date (approssimative) di inizio e fine di ciascun task, mentre ora ho solo il numero di giorni occupati. Devo fare un pò di ragionamenti.
Per cominciare, posso calcolare la frazione di mese che un task occupa: se in un mese ho 100 giornate disponibili, un task che in quel mese occupa 10 giorni va a riempire un decimo del mese. A questo punto, usando la funzione monthrange della libreria calendar, posso calcolare il numero di giorni contenuti in quel mese e fare la proporzione: il decimo di mese che ho calcolato prima, se un mese è di 28 giorni, vale circa 2,8 giorni. Naturalmente poi questi calcoli saranno tutti approssimativi, ma non importa.
Il mio obiettivo è costruire una lista di oggetti, uno per task. Ciascuno di questi oggetti deve contenere il nome del task, la data di inizio e la data di fine. Facciamo un bel loop sulla lista dei task, per ciascun task isoliamo dalla lista costruita in precedenza tutti i mesi che contengono attività per quel task, e di questa lista prendiamo il primo elemento (mese di inizio) e l'ultimo (mese di conclusione, che potrebbe anche coincidere col mese di inizio). Recuperiamo entrambi i mesi come oggetto datetime, e per ciascuno calcoliamo anche il numero di giorni contenuti.
dicts = []
for index, task in enumerate(tasks):
records = months.loc[months[task['activity']] != 0]
records = records.loc[~records.index.isin(['Total'])]
if (records.empty):
continue
starting_month = datetime.datetime.strptime(records.iloc[0]['month'], '%Y-%m').date()
starting_month_days = monthrange(starting_month.year, starting_month.month)[1]
ending_month = datetime.datetime.strptime(records.iloc[-1]['month'], '%Y-%m').date()
ending_month_days = monthrange(ending_month.year, ending_month.month)[1]Per calcolare la data di inizio dobbiamo estrapolare i giorni occupati da eventuali task precedenti che hanno occupato giorni in quel mese, e poi riproporzionare sul numero di giorni effettivi del mese. Un bel +1 e abbiamo il giorno (approssimativo) di inizio del task nel mese.
# Giorni occupati nel primo mese da attività precedenti
preceding_days_in_month = sum([records.iloc[0][activity] for activity in [preceding_task['activity'] for preceding_task in tasks[0:index]] ])
if (preceding_days_in_month == 0):
starting_day = 1
else:
starting_day = int(starting_month_days * preceding_days_in_month / records.iloc[0]['days_avail_tot']) + 1
starting_month = starting_month.replace(day=starting_day)Per calcolare la data di fine procediamo a ritroso. In questo caso dobbiamo considerare i giorni occupati nel mese da task successivi, ed eventuali giorni rimasti inutilizzati (la colonna days_avail), il tutto poi sempre riproporzionato ai giorni da calendario del mese contro i giorni calcolati da FTE.
# Giorni occupati nell'ultimo mese da attività successive
following_days_in_month = sum([records.iloc[-1][activity] for activity in [preceding_task['activity'] for preceding_task in tasks[index+1:]] ])
# Eventuali giorni in avanzo se mese non completamente occupato
following_days_in_month += records.iloc[-1]['days_avail']
if (following_days_in_month == 0):
days_after = 0
else:
days_after = int(ending_month_days * following_days_in_month / records.iloc[-1]['days_avail_tot'])
ending_day = ending_month_days - days_after
ending_month = ending_month.replace(day=ending_day)A questo punto aggiungiamo i dati di questo task al nostro dizionario di date, e chiudiamo il loop.
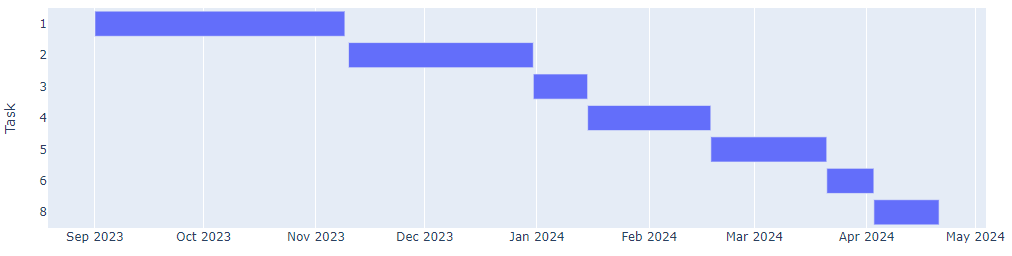
dicts.append(dict(Task=task['activity'], Start=starting_month, Finish=ending_month))Andiamo a stampare il risultato, e sarà qualcosa del genere:
[{'Task': '1', 'Start': datetime.date(2023, 9, 1), 'Finish': datetime.date(2023, 11, 9)}, {'Task': '2', 'Start': datetime.date(2023, 11, 10), 'Finish': datetime.date(2023, 12, 31)}, {'Task': '3', 'Start': datetime.date(2023, 12, 31), 'Finish': datetime.date(2024, 1, 15)}, {'Task': '4', 'Start': datetime.date(2024, 1, 15), 'Finish': datetime.date(2024, 2, 18)}, {'Task': '5', 'Start': datetime.date(2024, 2, 18), 'Finish': datetime.date(2024, 3, 21)}, {'Task': '6', 'Start': datetime.date(2024, 3, 21), 'Finish': datetime.date(2024, 4, 3)}, {'Task': '8', 'Start': datetime.date(2024, 4, 3), 'Finish': datetime.date(2024, 4, 21)}]Non ci resta altro da fare che dare questo dizionario in pasto a plotly.
fig = px.timeline(dicts, x_start="Start", x_end="Finish", y="Task")
fig.update_yaxes(autorange="reversed")
fig.show()E voilà!
Alla prossima!