
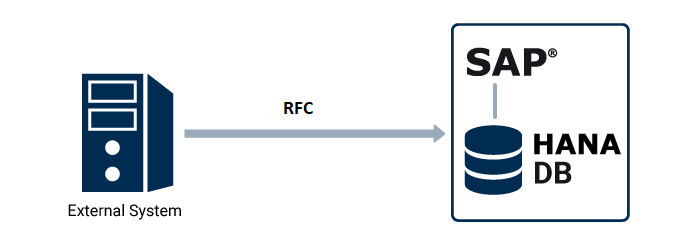
Leggere una tabella SAP da Python mediante RFC
Python è comodo per elaborare dati, ma questi dati bisogna procurarseli in qualche modo. Se i dati sono contenuti in una tabella su un sistema SAP S/4, il metodo più diretto è chiamare un modulo RFC.
Requisiti
Per chiamare un modulo RFC da Python è necessario installare nel sistema la Netweawer RFC SDK. Questa libreria è scaricabile da qui, ma il download richiede un S-USER valido (no free trial) e che sia abilitato al download di risorse. Se il vostro S-USER non è abilitato (come accade di solito) dovete chiedere per piacere agli IT della vostra organizzazione.
Si installa e si prende nota della cartella di installazione.
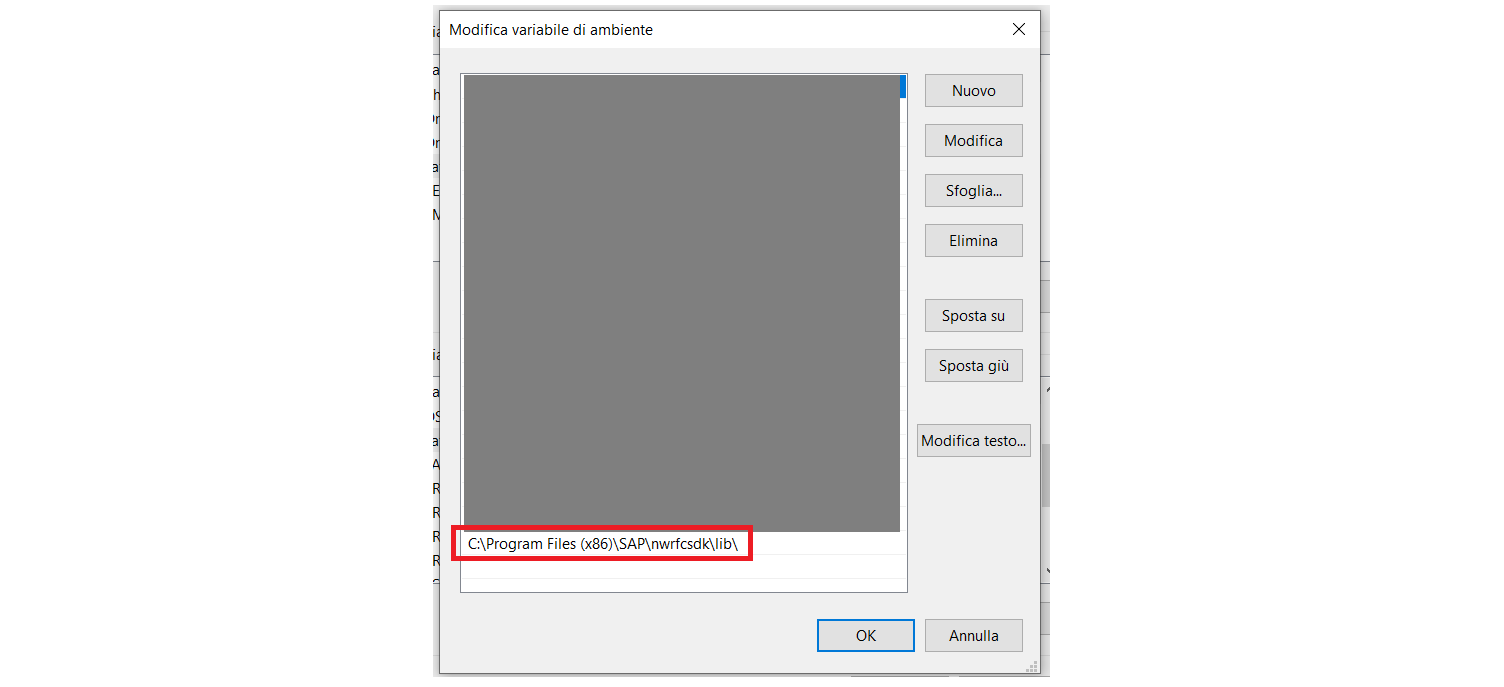
Bisogna poi aggiungere la cartella "lib" della nostra installazione nel path di sistema. Su Windows, si apre il pannello di controllo, voce "Sistema e Sicurezza", voce "Sistema", "Impostazioni di sistema avanzate". Nel tab "Avanzate" si preme il pulsante "Variabili d'ambiente...". Nella parte bassa della finestra (Variabili di Sistema) si fa doppio click su "path", e nella finestra che si apre si aggiunge una riga che punta alla cartella di cui sopra.
Bisogna inoltre installare la libreria Python PYRFC, ad esempio con pip:
pip install pyrfcA questo punto siamo pronti a cominciare. Usando la libreria pyrfc possiamo chiamare qualunque function module abilitato per la comunicazione RFC. Possiamo crearne uno noi, o possiamo usarne uno standard: nel nostro caso esiste già un modulo che permette di leggere il contenuto di una tabella SAP, e si chiama "RFC_READ_TABLE". Possiamo richiamarlo con questo codice:
from pyrfc import Connection
conn = Connection(
ashost='xxx.xxx.xxx.xxx',
sysnr='00',
client='XXX',
user='xxxxx',
passwd='yyyyy'
)
table='MARA'
delimiter = '|'
response = conn.call(
"RFC_READ_TABLE",
QUERY_TABLE=table,
DELIMITER=delimiter,
FIELDS=[{'FIELDNAME':'MANDT'},{'FIELDNAME':'MATNR'}]
)
conn.close()Nota: questo FM ha parecchie limitazioni, come ad esempio il fatto che ogni record restituito non può essere più lungo di 512 caratteri. In questo caso, visto che la MARA è una tabella con millemila colonne, abbiamo usato il parametro "FIELDS" per limitare le colonne lette.
A questo punto, nella variabile "response" troviamo un dizionario che contiene, tra le altre, le chiavi DATA e FIELDS.
La chiave FIELDS contiene l'elenco dei campi letti dalla tabella, con il tipo e la posizione all'interno della risposta. Ogni record della risposta, come vedremo dopo, è infatti costruito come stringa in cui i campi sono separati dal separatore specificato al momento della chiamata, e in FIELDS è presente per ciascun campo il carattere di inizio e la lunghezza.
print(response['FIELDS'])
[{'FIELDNAME': 'MANDT',
'OFFSET': '000000',
'LENGTH': '000003',
'TYPE': 'C',
'FIELDTEXT': 'Mandante'},
{'FIELDNAME': 'MATNR',
'OFFSET': '000004',
'LENGTH': '000040',
'TYPE': 'C',
'FIELDTEXT': 'Codice materiale'}]Nella chiave "DATA" sono invece presenti le righe lette:
print(response['DATA'])
[{'WA': '100|TG10'},
{'WA': '100|TG11'},
{'WA': '100|TG12'},
{'WA': '100|TG13'},
{'WA': '100|TG14'},
{'WA': '100|FG129'},
{'WA': '100|SM0001'},
{'WA': '100|NS0002'},
....A questo punto abbiamo in mano tutto quello che ci serve per gestire queste informazioni in Python. Ad esempio, potremmo usare le informazioni relative ai campi e alla loro lunghezza per trasformare le righe in dizionari:
data = []
for orig_record in [record['WA'] for record in response['DATA']]:
parsed_record = {}
for field in response['FIELDS']:
parsed_record[field['FIELDNAME']] = orig_record[int(field['OFFSET']):int(field['OFFSET'])+int(field['LENGTH'])].strip()
data.append(parsed_record)Potremmo invece trasformare l'output direttamente in un dataframe Pandas, per facilitare successive analisi. Si può ottenere questo risultato con questo comodo snippet:
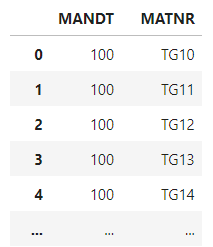
import pandas as pd
result = pd.DataFrame(
[[x.strip() for x in response['DATA'][n]['WA'].split(delimiter)] for n in range(len(response['DATA']))],
columns=[x['FIELDNAME'] for x in response['FIELDS']]
)Questo il risultato:
Alla prossima!