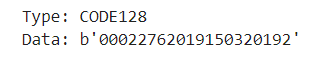Individuazione barcode con Python
Supponiamo di avere un documento PDF, e supponiamo che su questo documento sia stato incollato un barcode. L'obiettivo è estrarre il contenuto del barcode dal documento in maniera automatica con Python.
Ci serviranno due librerie: pyzbar per l'estrazione e interpretazione del barcode e pdf2image per trasformare le pagine del pdf in immagini. Le possiamo installare come di consueto:
pip install pyzbar pdf2imagePdf2image richiede per il suo funzionamento che sul sistema sia presente Poppler. Poppler è una libreria open source per lavorare con i PDF. È possibile scaricare i binari direttamente dal sito (https://poppler.freedesktop.org/). Non è richiesta nessuna installazione, è sufficiente scaricare lo zip (nel nostro caso per Windows) ed estrarlo da qualche parte.
Possiamo iniziare.
Per prima cosa importiamo le funzioni necessarie dalle librerie:
from pyzbar import pyzbar
from pdf2image import convert_from_pathDopodiché trasformiamo il pdf in una lista di immagini. Dobbiamo naturalmente usare il nome del nostro file come primo parametro, e il path in cui abbiamo copiato i binari di Poppler. Il secondo parametro rappresenta i DPI della conversione in immagine, di solito 500 è un valore corretto per questo tipo di analisi.
pages = convert_from_path(
'documento.pdf',
dpi=500,
poppler_path=r'C:\poppler-0.68.0\bin'
)A questo punto possiamo prendere la prima pagina (pages[0]) e darla in pasto a pyzbar.
decoded_objects = pyzbar.decode(pages[0])Per concludere, possiamo stampare il risultato dell'analisi, ad esempio così:
for obj in decoded_objects:
print("Type:", obj.type)
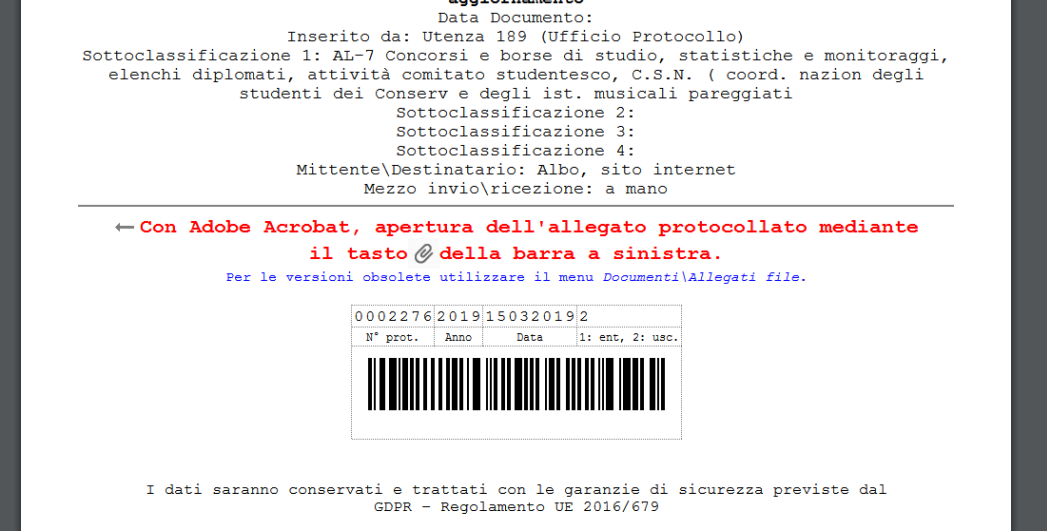
print("Data:", obj.data)Facciamo una prova con un PDF trovato a caso su google. In prima pagina campeggia un barcode, e chi ha preparato il documento è stato così gentile da scriverci sopra la decodifica.
E questo è il risultato!