
Impostare un backup online al nostro server Linux
Il cloud è una cosa fantastica: posso caricare i miei files e, come per magia, non devo più preoccuparmi di computer, ups, dischi che si usurano, backup, i ladri in casa. Tutto questo sarebbe fantastico se non fosse per il fatto che il cloud, ahimè, è composto a sua volta da computer. Computer si possono rompere, che possono essere sequestrati per compiacere un partner importante, che possono andare a fuoco perchè ammucchiati in container, che possono perdere i dati. E' per questo che è importante, anche per chi usa servizi online, premurarsi di avere comunque un backup altrove, in un datacenter diverso.
Per il mio vps, che uso come storage di documenti ed ebooks (addio Dropbox, ti ho voluto bene ma costi troppo), ho studiato una soluzione con l'ottimo Backblaze.

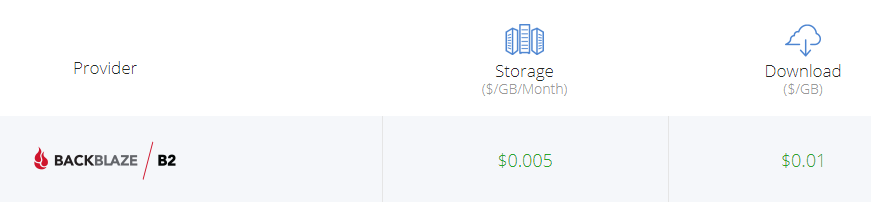
Backblaze è una azienda americana specializzata in soluzioni di archiviazione online, e offre un servizio di storage (B2 Cloud Storage) scalabile dalla piccola soluzione personale a interi backup aziendali. Come spesso accade, la fatturazione è legata allo spazio occupato (in questo caso 0,5 centesimi di $ al GB al mese) e alla banda in download (che si usa solo quando c'è davvero da recuperare quanto perso, e a quel punto ben venga spendere 1 centesimo di $ al GB). E i primi 10GB sono pure gratis!
Per implementare una soluzione del genere il primo passo è creare un account su backblaze.com e attivare il servizio B2 Cloud Storage.
Poi bisogna creare un "bucket", ovvero un contenitore che andrà ad ospitare i dati relativi al nostro backup (i bucket sono usati per separare i dati, anche con l'impostazione di permessi diversi).
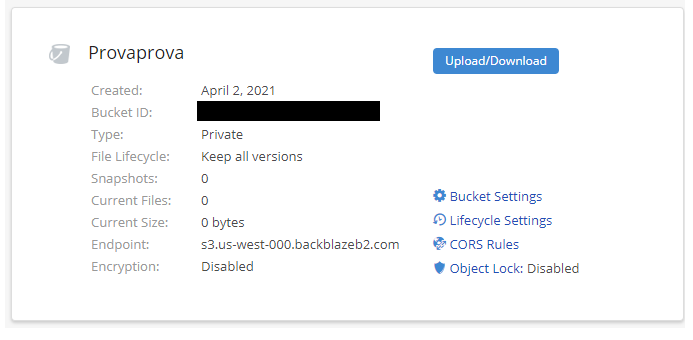
Diamo al bucket un nome qualunque, lo impostiamo come privato e disattiviamo le funzionalità accessorie proposte.
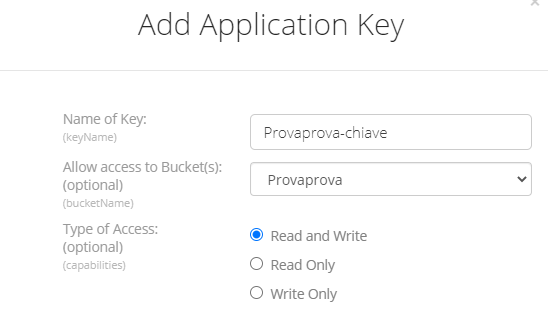
A questo punto dobbiamo generare una chiave per consentire alla nostra applicazione di backup di accedere al nostro bucket (usando una chiave applicativa possiamo evitare di inserire nell'applicazione le nostre credenziali. Inoltre possiamo limitare l'accesso al singolo bucket interessato, proteggendo gli altri). Andiamo nella sezione "App keys", creiamo una chiave principale...

..e poi a partire da questa creiamo una chiave secondaria apposta per il nostro backup.

Diamo alla chiave un nome qualunque e gli diamo accesso in lettura/scrittura al solo bucket interessato:
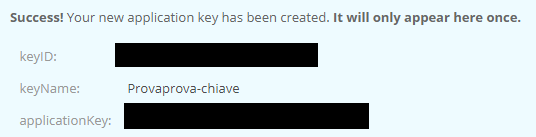
Attenzione: al momento della creazione della chiave vengono mostrati dei parametri. E' fondamentale prendere nota, poichè non sarà più possibile rivederli.
A questo punto passiamo al software di backup. Sulla mia VPS Linux ho installato Restic: è un software di backup open source da riga di comando e supporta nativamente i bucket Backblaze.
Una volta installato, si procede alla configurazione seguendo le comode indicazioni. Per prima cosa si creano due variabili d'ambiente (temporanee per la sessione in corso) contenenti i parametri di accesso al nostro account (rispettivamente il keyID e applicationKey mostrati quando abbiamo creato la nuova chiave applicativa). Già che ci siamo mettiamo anche il nome del nostro bucket, così non dovremo inserirlo dopo.

Adesso che abbiamo in sessione le credenziali possiamo inizializzare il backup Restic sul nosto bucket.
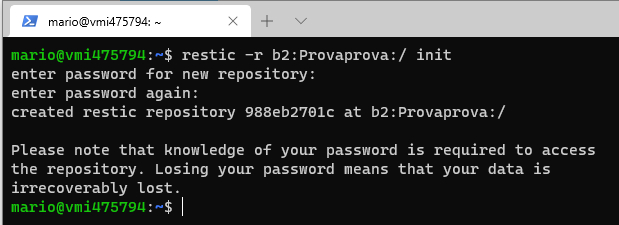
Durante la creazione del repository è richiesta la creazione di una ulteriore password, che sarà quella con la quale vengono cifrati i file che vengono caricati. Inutile dire che, se questa password è smarrita, il backup è totalmente irrecuperabile. La salviamo in un file, per averla a disposizione di Restic senza doverla digitare ogni volta. In questo esempio abbiamo chiamato il file "password.txt".
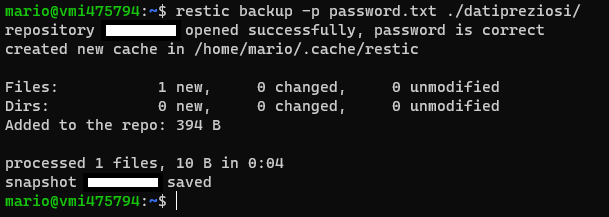
A questo punto (visto che abbiamo le credenziali già in variabili di sessione) possiamo avviare un backup semplicemente usando il comando:
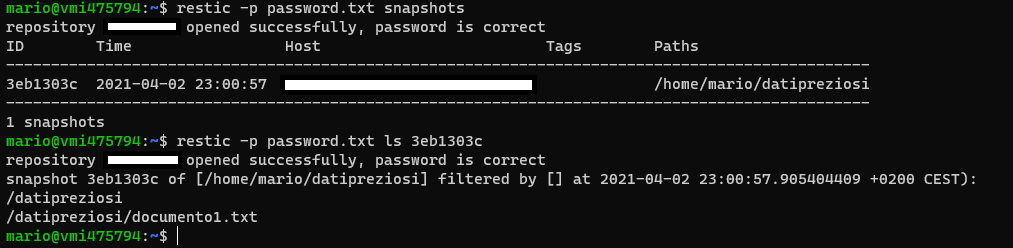
I backup sono incrementali: ogni operazione successiva crea un nuovo "snapshot" e copia solo i file che sono stati modificati. E' possibile mostrare la lista degli snapshot effettuati con il comando "snapshots", ed è possibile visualizzare l'elenco dei file contenuti in uno snapshot con il comando "ls" (specificando l'id dello snapshot). NB: in ciascuno snapshot sono elencati TUTTI i files attualmente presenti nel backup; lo snapshot non indica quali sono i dati "nuovi", bensì qual'è lo stato complessivo del backup in quell'istante temporale.
Per concludere, è possibile recuperare l'intero contenuto del backup con il comando "restore":

Per concludere, è possibile (e auspicabile) automatizzare la procedura di backup creando un unico file bash che verrà poi richiamato da cron. Una cosa del tipo:

Ricordatevi, i backup salvano le vite. Fateli. Anche se i vostri dati sono sul cloud. Anzi, specialmente se i vostri dati sono sul cloud.